esCOVID19data, compromís amb les dades de la pandèmia
19 maig, 2021 - Mariluz Congosto, professora Honorífica del Departament d’Enginyeria Telemàtica la UC3M i professora en l’O-Tad i Aniol Maria, tècnic a l'Arxiu Municipal de Reus
El projecte esCovid19data va fer la seva presentació al 18è Congrés d’Arxivística i Gestió de Documents de Catalunya tot mostrant les vicisituds i reptes de la recopilació i difusió de dades sobre la pandèmia de Covid-19
Seria un 13 de març de 2020 que finalment vam rebre l’avís definitiu que feia dies que temíem i era que ens enviaven cap a casa a complir amb un confinament total. La pandèmia s’havia estès per tot el país i ja no eren només uns casos puntuals de gent que havia estat de viatge a zones amb focus actius de Covid-19.
Hi ha qui s’ho va agafar com uns dies de frustració paranoide, d’altres van provar sort a veure si podien escapar-se del confinament anant a comprar o passejant el gos. Però també hi havia gent que buscava saber què estava passant, i especialment en el cas dels tècnics amb tractament i visualització de dades van ser uns dies de grans sorpreses i experimentació perquè de cop rebien el focus mediàtic més gran que havien vist fins llavors, i tot d’iniciatives de divulgació d’informació sobre la pandèmia anaven sorgint arreu.
D’entre les iniciatives n’hi va haver una en concret que no només divulgava gràfics i infografies, sinó que es va proposar oferir un lloc on oferir les dades el més accessible i útils possibles. No recordo el dia exacte que vaig entrar a formar-ne part, però la publicació a Twitter de Javier Cantón indicaria que seria cap al 19 de març de 2021 que ens assabentaríem de forma oberta de l’existència del que s’anomenaria esCOVID19data.
En aquells dies el grup esCovid19data s’estava plantejant un model d’amadrinament de comunitats autònomes per tal de distribuir la tasca de recopilació i normalització de les dades sobre la pandèmia. Fins aquell moment, aquesta recollida era extraient dades dels mitjans de comunicació i fonts molt heterogènies, però al cap de pocs dies s’aniria formant aquest entramat de voluntaris que procurarien també fer peticions i recerca de fonts més automàtiques i oficials, en el millor dels casos aconseguint que s’accelerés la publicació de datasets en portals de transparència i dades obertes institucionals. No va ser possible en totes les comunitats autònomes i províncies, però es va procurar sistematitzar gran part de les que sí que complien els mínims requeriments i estàndards.
No només era l’obtenció de datasets, sinó que també es va anar establint una estructura organitzativa que aniria optimitzant els scripts i rutines que recopilaven i normalitzaven tot aquest gran volum de dades. Es formaria així diversos nivells o càrregues de treball, uns voluntaris dedicats a amadrinar l’obtenció de dades de comunitats autònomes, uns altres que es dedicarien a la tasca de manteniment de codis d’actualització automàtica, i també en podríem anomenar uns altres de suport puntual en temes concrets siguin de difusió o de captació de nous suports per tasques concretes.
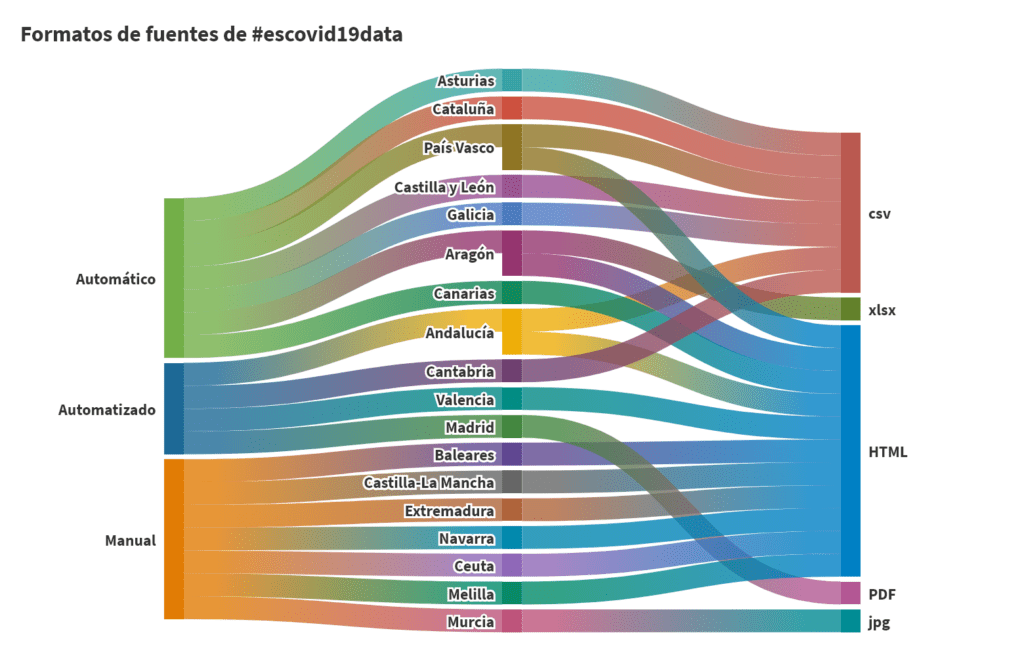
Hem de parlar concretament de les dades. Ja que el projecte s’ha trobat amb diverses problemàtiques i vicissituds al llarg de l’any i poc d’existència. Primerament parlar de les confusions i a vegades poca claredat en els camps en els datasets. Han sigut diverses les ocasions en què s’ha hagut de fer una reflexió sobre les dades d’ingressos en UCI o defuncions que apareixien publicades amb diversos criteris i formats variats segons la comunitat autònoma. Però aquesta incertesa s’ha anat multiplicant a mesura que apareixien noves variables: nombre de contagis, hospitalitzacions, recuperacions, defuncions, i un llarg etcètera. Que ha arribat fins i tot a la disparitat de què algunes comunitats autònomes no només publicarien per províncies sinó també per àrees sanitàries que no coincidien necessàriament del tot amb una mateixa província, i que oferien també una nova varietat d’informació que podia ser interessant.
A més de la varietat de dades, també la varietat de criteris en la freqüència d’actualització, la diversitat de formats,… Perquè tot i que hem tingut casos exemplars on es publicaven les dades en formats reutilitzables i accessibles per API, per altra banda també ens hem trobat amb casos molt dramàtics en què les dades apareixien en format d’imatge JPG o en PDF que ha obligat a fer ús d’eines i tècniques com scrapping i rastreig de les dades per incorporar-les a la base de dades d’esCovid19data.
Bàsicament el grup s’ha organitzat per un canal de Telegram molt actiu on es debaten diàriament temes i s’organitzen les publicacions de noves dades i infografies amb la direcció en un primer moment de Pablo Rey i que després agafaria el relleu David Rodriguez. I uns repositoris Git que dirigeix l’organització Montera34, on s’han anat apuntant i acumulant les dades recollides dia a dia. Cal dir que l’accés al grup és obert i segueix reclutant voluntaris que puguin ajudar amb qualsevol tasca, no només en la part més tècnica de recollida i treball amb les dades sinó també en difusió d’aquestes i organitzatives com el contacte amb diversos col·lectius també relacionats amb dades sobre la pandèmia de Covid-19.
De feina tot i l’automatització encara n’hi ha molta per fer, ja que el manteniment només dels scripts ja s’enduen diverses hores al dia el seu funcionament (es tenen comptabilitzats uns 720 gràfics actualitzats diàriament), i a vegades sorgeixen problemàtiques quan les fonts de dades varien sigui per l’adreça URL o pels camps publicats. És per això que el grup va començar a participar en podcasts i a intervenir en actes i congressos per explicar-se i animar a nous membres perquè s’hi unissin, ja que es necessiten molts perfils diversos, tal com mostra que actualment a esCovid19data s’hi pugui trobar sociòlegs, periodistes, enginyers, arxivers, informàtics, entre d’altres. I la ponència de Mariluz Congosto i Aniol Maria al 18è Congrés d’Arxivística i Gestió de Documents de Catalunya, va ser una mostra més d’aquesta entrega a explicar-nos i motivar a la incorporació d’encara més voluntariat.
En la ponència, vam poder fer un repàs de tota la història del grup i de les problemàtiques que s’havien anat topant. Però també dels encerts, i oferint aquesta base de dades immensa d’esCovid19data que permet consultar quins han sigut els canvis de cada dia i els estats anteriors sobre diverses dades de la pandèmia. Un projecte de documentació del procés i esdeveniment històric que ara es pot oferir a tota persona interessada, amb la seva traçabilitat, verificabilitat, control de versions, transparència i usabilitat assegurades.
També explicant que s’havia arribat fins i tot a fer públic un “Manifiesto por unos datos públicos accesibles para la construcción de un conocimiento compartido en tiempos de pandemia global“, en el qual es resumiren per punts les reclamacions que seria necessari resoldre i errors que seria ideal que no es tornessin a repetir. Entre aquestes i ja conegudes pel món de les dades, es comentava que les administracions públiques oferissin les dades de forma estructurada, oberta, clarament vinculada i contextualitzada amb les agències i entitats governamentals encarregades de la seva integració, garantir la deguda anonimització i protecció de dades, l’establiment de criteris que definissin si es publica a escala provincial o per àrea sanitària, que es fes ús de repositoris oberts que poguessin ser corregits, registrats i traçar-ne els canvis realitzats. Que l’accés fos lliure i fàcil de compartir, l’actualització constant i recent en la mesura del possible, i sobretot la transparència en la presa de decisions que afectin la publicació de les dades per tal de ser els més honestos possibles i evitar les suspicàcies que tant de mal han fet en l’opinió pública sobre la pandèmia.
Finalment vam animar a qualsevol persona que en volgués formar part de forma voluntària al grup que consultés el nostre perfil a Twitter @escovid19data, i a participar del canal de Telegram on es continua treballant constantment en la recopilació i disposició de dades sobre la pandèmia de Covid-19. Perquè d’aquí poc vindrà la fase de preservació de totes aquestes dades, i el perfil arxivístic ja està sent cridat i consultat dins del grup perquè aporti els seus coneixements i experiència per tal que no es perdi tota la feina feta.
Deixa un comentari