Records in Context, cap a un model conceptual d’alt nivell
9 desembre, 2021 - Aniol Maria Vallès, arxiver de l'Arxiu Municipal de Reus i membre del Grup de Treball sobre Transparència i Dades Obertes de l’AAC-GD
El model conceptual RiC és ara mateix un plantejament obert al debat i a les aportacions dels professionals de l’arxivística, i, per tant, tothom està convidat a participar i expressar-hi el seu parer
En un món en el qual vivim rodejats d’aparells que capten informació de múltiples fonts per oferir-nos informació personalitzada, sembla una bona idea orientar el que oferim des dels arxius cap a aquest model de comunicació tan demandada per la societat. Ja no es tracta de publicar fitxes estàtiques amb descripcions esquemàtiques que amb prou feines s’enllacen amb altres fitxes d’altres portals però sense l’obertura de les dades. I és en això que el model conceptual de Records in Contexts ens pot aportar un marc o espai perquè desenvolupem aquesta aportació dels arxius a la societat com autoritats i custòdia de coneixement.
Molt encertadament, l’Associació de Professionals de l’Arxivística i la Gestió de Documents de Catalunya, va organitzar a finals de novembre i fins a inicis de desembre d’aquest 2021 un “Curs sobre model RiC: introducció al model” que ens va oferir l’Ana López Cuadrado, cap del Departament de Coordinació i Normalització del Archivo Histórico Nacional i que també forma part de l’equip de govern del Stichting Archives Portal Europe Foundation i coordina el grup de treball sobre estàndards d’aquesta mateixa fundació.
En el curs l’Ana López, incidí primerament en la necessitat del context normatiu i digital en què ens trobem, la web semàntica i com funciona el model RiC, i en com aquest podia encaixar en els models i esquemes ja preestablerts en la descripció arxivística. Que no era un “borrón y cuenta nueva” sinó que RiC suposava una aportació amb visió global a la descripció arxivística.
Des de l’accés a la informació com a finalitat clara dels arxius, de forma normalitzada, identificable, cercable i accessible, per tal que la informació pugui ser dades, ja sigui amb Sistemes de Gestió Documental com amb Bases de Dades; el model RiC sembla ser una nova manera d’entendre les descripcions en què els conceptes significatius passen a ser enllaçables i relacionats de forma directa entre ells. Passant de les dades simplement enllaçades en les quals un concepte apareixia vinculat a una altra pàgina, a les dades obertes enllaçades en què els vincles van directes de concepte a concepte podent establir així jerarquies i relacions de parentiu entre els quals.
L’Ana López aportà exemples molt interessants d’aplicació, no només per enriquir els portals d’arxiu, sinó també per potenciar l’accessibilitat de les dades que contenen aquestes descripcions, i fer-les processables pels sistemes d’aprenentatge automàtic i també pels serveis de consulta bàsica a tota mena d’usuaris. Anant més enllà de l’usuari experimentat que pot arribar a conèixer fins i tot eines internes de l’arxiu com el Quadre de Classificació, i facilitant l’accés a la documentació a tota mena d’usuaris interessats en temes diversos. És així com s’ha pogut parlar també al curs sobre el dret a l’accés a la informació i com afecta molts temes diversos com els drets d’autor, el codi obert, la privacitat, la seguretat de la informació,… i els reptes que això ens suposarà. De com el perfil dels usuaris ha canviat i ja no és un accés d’erudits, sinó que ara rebem usuaris neòfits que també és important que coneguin com funciona l’arxiu.
Es va parlar de com tots els nostres sistemes han de conversar entre ells i entendre’s en la quantitat més gran d’idiomes. I això és clau quan els nostres mateixos sistemes es componen per múltiples bases de dades relacionades i obertes o no al públic, amb multitud de regles i normatives. Cosa que requereix professionals molt formats amb coneixements especialitzats, que hauran de treballar amb informació sense definir ni normalitzar, amb soroll i falta d’organització. Per tant, és necessari aconseguir la normalització per assolir una millora clara en l’accés a la informació.
Amb l’evolució d’Internet en versions, la 1.0 com la inicial de pàgines estàtiques, la 2.0 com a la introducció de dinamisme en les pàgines, i la 3.0 com la del teixit de grans bases de dades interrelacionades; el curs sobre RiC va servir per posar de manifest que hem de participar en aquesta nova versió de la xarxa. Amb tot de models de connectivitat en plena interacció, amb la descentralització dels sistemes, la web semàntica, i tants conceptes que poden semblar molt nous, però que en arxius ja coneixem a causa del nostre llegat històric de transmissió del coneixement arreu.
La normalització i estandardització dels conceptes mateixos dins de les descripcions de documents amb la normativa i models conceptuals dels sistemes RiC, ens aportarà beneficis com millores en l’accés a la informació arxivística, a les dades, a la consulta, l’ús i la reutilització. Amb exemples com Archives Portal Europe, Europeana Collections i Social Networks and Archival Context, que se centren a presentar els documents en el seu context que és el que realment cerquen els usuaris. Tal com va indicar una de les diapositives del curs “too complex, too forgiving, and too flexible for its own good”. És a dir, passar de la complexitat i massa permissivitat de sistemes com EAD, que eren massa flexibles per acabar sent bons per un ús generalitzat, a establir uns corpus d’ontologies i tesaurus normalitzats i unificats entre els diversos centres i autoritats arxivístics que permetin una millor interoperabilitat i, per tant, un enriquiment mutu. I així facilitar el que els productors de documentació necessiten que és que la seva informació o servei sigui visible, útil i rellevant. Que es pugui reutilitzar la informació d’altres per augmentar la capacitat del servei. Que es pugui compartir de manera senzilla i que no es requereixi massa complexitat.
El model RiC no té per què ser un gran sotrac, ja que com ve sent el costum segueix el llenguatge XML i vam poder veure com per exemple els elements anaven amb claus angulars < i >, així com els atributs anaven precedits d’una arrova @, i a més pot ser directament relacionable amb ISAD(G), iSAAR(CPF), ISDF, ISO 23081 i tots els estàndards anteriors. Això vol dir que si fem el pas no hauria de resultar difícil llegir-ne un exemple fet i saber com ens adaptarem a aquesta nova metodologia de descripció que de fet es basa a introduir aquests conceptes interrelacionats amb enllaços. No és un començar de bell nou sinó una visió global de cap on hauria de dirigir-se aquesta difusió del que tenim descrit.
Com a model conceptual d’alt nivell, centrat en la identificació i descripció intel·lectual dels documents d’arxiu, de les persones que els crearen i els usaren, de les activitats acomplertes per les persones que els documents d’arxiu faciliten i documenten, això fa que RiC sigui un model conceptual d’alt nivell que afectarà per sobre d’altres oferint una visió intel·lectual que no baixa, però a la unitat física i deixa aquest nivell més baix a altres normatives que serveixin més per aquestes unitats físiques. RiC aborda necessàriament la descripció de la plasmació o representació física de les entitats documentals, però no cobreix tots els seus atributs i relacions que seran necessaris per gestionar físicament la instal·lació dels documents.
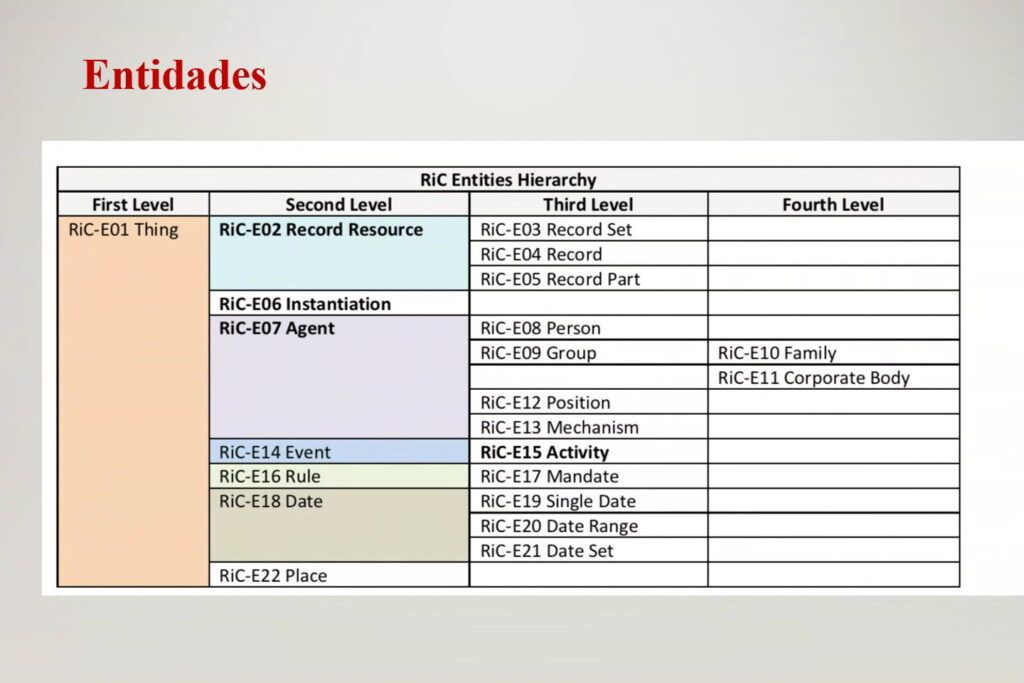
Per exemple, RiC no es limita a documents analògics o digitals sinó que serveix per a ambdós alhora, ja que s’espera que esdevingui una base per un accés integrat, descrivint des de la base de “coses” (els elements en si), les “entitats” (els seus atributs) i les “relacions” (els vincles amb altres elements). Així les entitats documentals (record resource) són la prova (instantation) de la realització d’una activitat (activity) per un agent (agent). I identificar i descriure els agents, les activitats que realitzen i els documents generats en el curs d’aquesta actuació, és, per tant, una responsabilitat fonamental dels gestors de documents i personal d’arxius. El que descrivim, inclourà totes les entitats possibles o estarà associat a una activitat. Descriurem i referenciarem les entitats i les descriurem en el seu context.
Però també acabarem abordant dilemes com per exemple elements de la descripció que podríem discutir, començant per les dates extremes o la cronologia específica dels documents, la seva autoria, la seva funció sobretot si és la de generació de tot un fons nou documental i les seves repercussions, arribant a haver de pensar si una fotografia incrustada en un document és també un document únic en si mateixa, o en el cas que ens arribi adjunta a un correu electrònic. Haurem de definir objectes digitals com els fitxers comprimits ZIP o RAR que ens desafiaran sobre si són documents simples o compostos, o com els fluxos de bits conflueixen i acaben component un arxiu que pugui assegurar la recuperació sense pèrdua alhora que se’l sotmet a tècniques que eliminen tuits.
Personalment, em va captar l’atenció que sembla que seguim avançant cap a un model distribuït de la informació (esperem que sigui el més cert possible) i cap a una major obertura i interoperabilitat de les dades que publiquem, amb portals que ja no haurien de caure en la redundància i la repetició de les mateixes fitxes descriptives sinó que poguessin compartir informació i incrustar-la entre els quals. Em va recordar molt al procés amb què es va originar projectes com el de WikiData en el cas de la Wikipedia, però també té moltes semblances amb la gestió de repositoris de codi estil Git que s’obre a la col·laboració i l’aportació de nova informació de forma distribuïda i federada, els projectes que giren al voltant de blockchain, les consultes a APIs, i també el crowdsourcing. Conceptes tots que es repeteixen sovint de forma saltejada per cridar l’atenció sobre qualsevol novetat tecnològica, tanmateix poques vegades veus integrables en una única proposta que aixoplugui tota un model conceptual com és el cas de Records in Context.
Com ens deia Ana López, el model conceptual RiC és ara mateix un plantejament obert al debat i a les aportacions dels professionals de l’arxivística, i, per tant, tothom està convidat a participar i expressar-hi el seu parer, per veure cap on evoluciona i quina acaba sent la seva implantació final. Mentrestant ens va deixar amb demostracions com PIAAF (Pilote d’interopérabilité pour les Autorités Archivistiques françaises) : démonstrateur o Explore – Social Networks and Archival Context, perquè ens n’anéssim fent a la idea.
Deixa un comentari